Neural Network Consoleによる学習済みニューラルネットワークの利用(その2)
識別機として作ったネットワークの中間層の値をエンコード値として使う、オートエンコーダもどきがつくりたかったのでテスト。
誤差関数には、y(OneHotにした3列のクラス値 )を入れているので、オートエンコーダではないが、実質的には同じもの
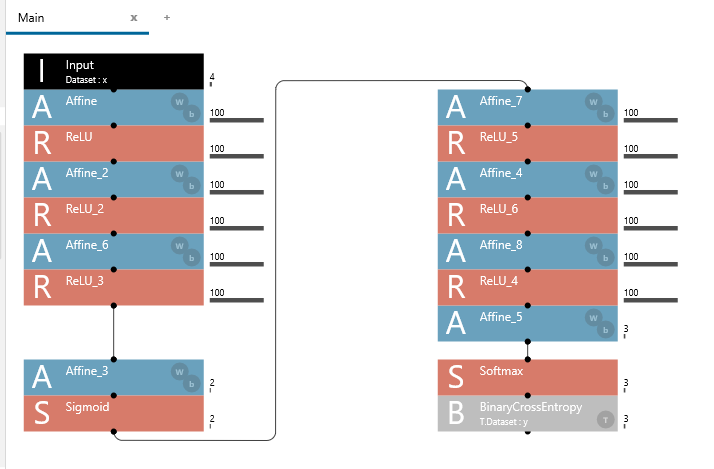
ネットワーク設計
ネットワークの設計とトレーニングはNeural Network Console(NNC)で実施。
2層では識別率が上がらなかったので、3層。
左側がエンコーダ、右側がデコーダ。
実行結果
(base) C:\dev\SampleCodes\hello_autoenc>python network.py 2020-05-23 12:39:58,407 [nnabla][INFO]: Initializing CPU extension... 2020-05-23 12:39:59,117 [nnabla][INFO]: Parameter load (<built-in function format>): C:\dev\SampleCodes\hello_autoenc\hello_autoenc.files\20200523_112705\results.nnp 入力データ(アヤメ3種類それぞれ1個づつ) [[4.3 3. 1.1 0.1] [4.9 2.4 3.3 1. ] [4.9 2.5 4.5 1.7]] もともとのネットワークの計算結果(エンコード+デコード) [[9.9999666e-01 1.6275737e-06 1.6897608e-06] [1.0858843e-05 9.9997306e-01 1.6078509e-05] [1.0666966e-05 1.2271330e-02 9.8771799e-01]] エンコードした値 [[1.8855007e-02 3.9558447e-08] [9.2018157e-01 1.9496704e-03] [9.9969387e-01 9.8213345e-01]] エンコードされた値をもとに、デコードした値 [[9.9999666e-01 1.6275737e-06 1.6897608e-06] [1.0858843e-05 9.9997306e-01 1.6078509e-05] [1.0666966e-05 1.2271330e-02 9.8771799e-01]]
ソースコード
訓練結果のloadコマンドの引数ファイルが、2年前とは変わっていた。
import nnabla as nn import nnabla.functions as F import nnabla.parametric_functions as PF def original_network(x, test=False): # Edit画面から、右クリック→Export→Python Code(NNC) # 引数yは削除 # def original_network(x, y, test=False): # Input:x -> 4 # Affine -> 100 h = PF.affine(x, (100,), name='Affine') # ReLU h = F.relu(h, True) # Affine_2 h = PF.affine(h, (100,), name='Affine_2') # ReLU_2 h = F.relu(h, True) # Affine_6 h = PF.affine(h, (100,), name='Affine_6') # ReLU_3 h = F.relu(h, True) # Affine_3 -> 2 h = PF.affine(h, (2,), name='Affine_3') # Sigmoid h = F.sigmoid(h) # Affine_7 -> 100 h = PF.affine(h, (100,), name='Affine_7') # ReLU_5 h = F.relu(h, True) # Affine_4 h = PF.affine(h, (100,), name='Affine_4') # ReLU_6 h = F.relu(h, True) # Affine_8 h = PF.affine(h, (100,), name='Affine_8') # ReLU_4 h = F.relu(h, True) # Affine_5 -> 3 h = PF.affine(h, (3,), name='Affine_5') # Softmax h = F.softmax(h) # BinaryCrossEntropy # h = F.binary_cross_entropy(h, y) return h def encorder_network(x, test=False): # original_networkの前半 # Input:x -> 4 # Affine -> 100 h = PF.affine(x, (100,), name='Affine') # ReLU h = F.relu(h, True) # Affine_2 h = PF.affine(h, (100,), name='Affine_2') # ReLU_2 h = F.relu(h, True) # Affine_6 h = PF.affine(h, (100,), name='Affine_6') # ReLU_3 h = F.relu(h, True) # Affine_3 -> 2 h = PF.affine(h, (2,), name='Affine_3') # Sigmoid h = F.sigmoid(h) return h def decorder_network(x, test=False): # original_networkの後半 # Input:x -> 2 # Affine_7 -> 100 h = PF.affine(x, (100,), name='Affine_7') # ReLU_5 h = F.relu(h, True) # Affine_4 h = PF.affine(h, (100,), name='Affine_4') # ReLU_6 h = F.relu(h, True) # Affine_8 h = PF.affine(h, (100,), name='Affine_8') # ReLU_4 h = F.relu(h, True) # Affine_5 -> 3 h = PF.affine(h, (3,), name='Affine_5') # Softmax h = F.softmax(h) return h # https://support.dl.sony.com/docs-ja/%E3%83%81%E3%83%A5%E3%83%BC%E3%83%88%E3%83%AA%E3%82%A2%E3%83%AB%EF%BC%9Aneural-network-console%E3%81%AB%E3%82%88%E3%82%8B%E5%AD%A6%E7%BF%92%E6%B8%88%E3%81%BF%E3%83%8B%E3%83%A5%E3%83%BC%E3%83%A9/ # nn.load_parameters(‘{training result path}/results.nnp’) nn.load_parameters( r"C:\dev\SampleCodes\hello_autoenc\hello_autoenc.files\20200523_112705\results.nnp") x = nn.Variable((3, 4)) x.d = [4.3, 3, 1.1, 0.1], [4.9, 2.4, 3.3, 1], [4.9, 2.5, 4.5, 1.7] print("入力データ(アヤメ3種類それぞれ1個づつ)") print(x.d) y_origin = original_network(x, test=True) y_origin.forward() print("もともとのネットワークの計算結果(エンコード+デコード)") print(y_origin.d) y_encoder = encorder_network(x, test=True) y_encoder.forward() print("エンコードした値") print(y_encoder.d) y_decoder = decorder_network(y_encoder, test=True) y_decoder.forward() print("エンコードされた値をもとに、デコードした値") print(y_decoder.d)
seabornを使ってみた
seabornを使ってみた。
plt.show(block=False) # これがないと表示されない。block=Falseがないとグラフを閉じるまでプログラムの実行が一時停止する。
ソースコード
import numpy as np import seaborn as sns from matplotlib import pyplot as plt x = np.random.normal(size=100) iris = sns.load_dataset("iris") sns.distplot(x, kde=False, rug=False, bins=10) plt.show(block=False) # これがないと表示されない。block=Falseがないとグラフを閉じるまでプログラムの実行が一時停止する。 sns.pairplot(iris) plt.show(block=False) # プログラムの終了とともにプロット画面も閉じてしまうので入力まち input()
結果
NasneからNASへの移行(速報版)
とりあえず最低限の目途はついたので、NasneからNASへのデータ移行メモ。
用途としては、録画データの延命。Nasneは古くなっていて、いつ壊れてもおかしくないので。
まだNasneからコピーしていない録画番組を選んでコピーや、コピーした番組の番組名ごとのディレクトリ分けのスクリプトはPythonで作成。もう少しきれいにしてから掲載予定。
移行先のNAS
QNAPのTS-453be。本体5万強。HDD別。4本必要。
TS-453Be | 幅広いアプリケーション拡張およびより優れた効率性を引き出すためのPCIeスロット付きのクアッドコアマルチメディアNAS | QNAP
追加購入のQNAP NASのアプリ。sMedio DTCP Move。税込み1100円。
sMedio DTCP MOVE
iPhoneでの再生環境用 税込み 1300円。※ 2020年12月時点で、iPadでは再生できないことを確認。
Media Link Player for DTV ~スマホでテレビを見よう~
できないこと
標準ではできないこと
スクリプトで解決できたこと
iPhoneのバックアップ先をDドライブへ
iPhoneのバックアップデータがCドライブの容量を食うので、iTunesが書き込むiPhoneのバックアップ先のディレクトリをDドライブに移動させる話。(公式ではないので自己責任で)
手順
大まかには、シンボリックリンクをつかって、iTunesが書き込むiPhoneのバックアップ先のディレクトリを別のドライブのディレクトリに化かす。
Windows10 Windowsストア版のiTunesむけ。
01. 既存のバックアップディレクトリを、別のドライブにコピーする。
既存のバックアップディレクトリ: "C:\Users\<ユーザディレクトリ名>\Apple\MobileSync\Backup"
から、
別のドライブ: "D:\keep\iTunesBackup"
に既存のバックアップファイルをコピーする。
robocopy /MIR "C:\Users\<ユーザディレクトリ名>\Apple\MobileSync\Backup" "D:\keep\iTunesBackup"
コピー完了後に、既存のバックアップディレクトリと別のドライブの容量やファイル数が一致することを確認する。
02. 既存のバックアップディレクトリをリネームする(最終的には削除する)
この後、既存のバックアップディレクトリと同名のシンボリックリンクを作るので、既存のバックアップディレクトリはなんでもいいので、別名にしておきます。
既存のバックアップディレクトリ: "C:\Users\<ユーザディレクトリ名>\Apple\MobileSync\Backup"
リネーム後: "C:\Users\<ユーザディレクトリ名>\Apple\MobileSync\Backup-old"
openpyxlで、エクセルファイルのフィルタの設定をする
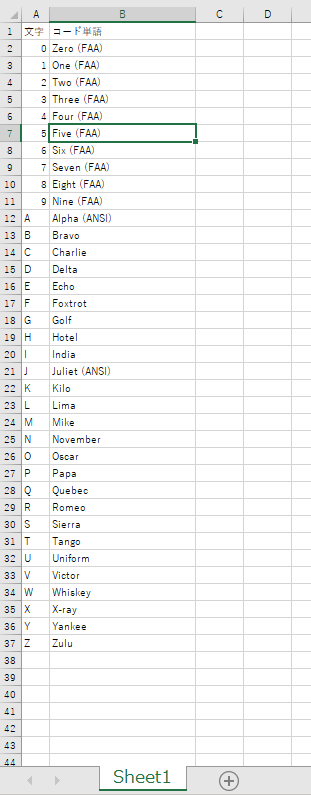
openpyxlで、エクセルファイルのフィルタの設定をする実証コード
エクセルで開いても、フィルタの設定は入っているが、フィルタ表示はされていない状態で表示される。
エクセルで開いて、フィルタのプルダウンを開いて、再適用すれば、フィルタリングされた状態で表示される。
コード
from openpyxl import Workbook, load_workbook, utils # 1行目がヘッダで、A2からデータが入っている想定 read_filename = r"C:\dev\SampleCodes\hello_openpyxl\NATO_phonetic_alphabet.xlsx" save_filename = read_filename.replace(".xlsx", "_filterd.xlsx") wb = load_workbook(read_filename) # 対象シートは 'Sheet1' ws = wb['Sheet1'] # フィルタを設定したい列名を指定 filter_col = 'A' # column_index_from_string(A)は1を返すが、使うときはオフセットで0始まりなので1を引いておく。 filter_col_offset = utils.column_index_from_string(filter_col) - 1 print("filter_col = {0}, filter_col_offset = {1}".format( filter_col, filter_col_offset)) # 表示したい行にある、A列の内容 # 実際にはない値を指定しても、add_filter_columnでは無視される。 filter_words = ["0", "A", "Z"] # データがある最大行を取得 max_row = ws.max_row max_col = ws.max_column print("max_row = {0}, max_col = {1}".format(max_row, max_col)) # 表示したい値が、実際にあるか確かめておく for word in filter_words: flag_find = False for row_index in range(0, max_row): cell_value = ws.cell( row=row_index+1, column=utils.column_index_from_string(filter_col)).value if word == str(cell_value): flag_find = True print("{0} in filter_words found".format(word)) break if flag_find == False: print("Error!! {0} in filter_words not found".format(word)) exit(-1) # 列番号をxlsの列名アルファベットに変換 max_col_letter = utils.cell.get_column_letter(max_col) # filterの範囲を指定 # A列からデータがあることが前提。 ws.auto_filter.ref = "A1:" + max_col_letter + str(max_row) print("ws.auto_filter.ref = {0}".format(ws.auto_filter.ref)) # filter指定 # filter_col_index は 0だと、ws.auto_filter.refの範囲で、いちばん左の列 ws.auto_filter.add_filter_column(filter_col_offset, filter_words) # サンプルコードにあったソートはしなくてよい。 # https://openpyxl.readthedocs.io/en/latest/filters.html#using-filters-and-sorts # ws.auto_filter.add_sort_condition("B2:B15") # 保存はする。 # エクセルで開いても、フィルタの設定は入っているが、フィルタ表示はされていない状態で表示される。 # エクセルで開いて、フィルタのプルダウンを開いて、再適用すれば、フィルタ表示される。 wb.save(save_filename) wb.close()
実行結果
(base) C:\dev\SampleCodes\hello_openpyxl>python hello_filter.py filter_col = A, filter_col_offset = 0 max_row = 37, max_col = 2 0 in filter_words found A in filter_words found Z in filter_words found ws.auto_filter.ref = A1:B37 (base) C:\dev\SampleCodes\hello_openpyxl>
順位を教えてくれる関数
順位を教えてくれる関数。
データ件数に対してn^2で計算時間がかかるようなので、大きな配列への適用は難しい。
自前環境での計算時間は大体以下の通り。
# 10000個で、0.2秒
# 20000個で、0.7秒
# 30000個で、1.5秒
# 40000個で、2.7秒
プログラム
import numpy as np import random import time # 1次元配列を渡したら、その配列の中での大きい順(一番大きな値に対しては1)を返してくれる関数。 # # 10000個で、0.2秒 # 20000個で、0.7秒 # 30000個で、1.5秒 # 40000個で、2.7秒 def calc_rank(data): np_data = np.array(data) rank = [None]*len(data) for index, value in enumerate(data): rank[index] = np.sum(np_data >= value) return rank def rand_list(length): rl = [None]*length for index in range(length): rl[index] = random.randrange(0, length*2) return rl if __name__ == "__main__": # data=[0,12,53,9,31,78,40,87,84,55,20,77] length = 1000 data = rand_list(length) tic = time.time() rank = calc_rank(data) toc = time.time() print("データ件数", length) print("計算時間(秒)", toc-tic) print("計算結果抜粋") for i in range(len(data)): print("{0} {1}".format(data[i], rank[i])) if i > 5: break # 印字は邪魔なので適当にbreak
実行結果
データ件数 12 計算時間(秒) 0.0 計算結果抜粋 0 12 12 10 53 6 9 11 31 8 78 3 40 7 87 1 84 2 55 5 20 9 77 4
Cisco スイッチコマンド備忘録
gwがスイッチの名前です。
Terminal(CUI関係)
terminal length 0
--More-- が出てくるときに。0にすれば全部一括で表示される。行数を指定できる。
DHCP関連
DHCPのリリース状況確認
show ip dhcp binding
固定IPの割り当て
configure ip dhcp pool pool_sample import all host 192.168.11.2 255.255.255.0 hardware-address 0123.4567.89AB dns-server 192.168.1.1 client-name pool_sample default-router 192.168.1.1 lease infinite end
hardware-addressは、DHCPのリリース状況確認で確認できる。
hardware-addressは、client-identifier となることもある。その時は、01+MACアドレス、のような値になっている。
自動割り当てされたIPの解除(MAC重複解除)
clear ip dhcp binding 192.168.11.2
よく使うのは、hardware-address を割り当てようとして、以下が出てきたときなど。
% A binding for this client already exists.
アクセスリスト関係
WAN側のInerfaceに設定すべきアクセスリスト
https://blog.redbox.ne.jp/cisco-acl-cbac.html
アクセスリストの設置場所、方向の話
アクセスリストを理解する
現在の設定のエクスポート(USBメモリを刺した状態で)
customer-config という名前のファイルでUSBメモリに保存される。
copy running-config usbflash0:customer-config
リモートアクセスVPN
Ciscoの資料。ステップ18 [ハッシュ アルゴリズム MD5 を使用してパスワードを暗号化する]のチェックを解除 をしないとつながらない。
https://community.cisco.com/t5/cisco-start-%E3%83%89%E3%82%AD%E3%83%A5%E3%83%A1%E3%83%B3%E3%83%88/%E3%83%AA%E3%83%A2%E3%83%BC%E3%83%88-%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9-ipsec-vpn-%E3%82%92%E8%A8%AD%E5%AE%9A%E3%81%99%E3%82%8B/ta-p/3292247