LINEのボット(実行基盤はAzure Functions)で作ってみたメモ
LINEのボット(実行基盤はAzure Functions,関数アプリ)で作ってみたメモ。 とりあえず、メッセージのテキストを取得して、オウム返ししてくるLINEボット。VSCodeを使わないと何もできない。
開発環境
Visual Studio Code を使用して Azure Functions を開発する | Microsoft Learn
上記の記載にあるように、VSCodeで作成。
- Visual Studio Code で F1 キーを押してコマンド パレットを開き、コマンド Azure Functions: Create New Project... を検索して実行します。 プロジェクト ワークスペースのディレクトリの場所を選択し、[選択] を選択します。
- HTTP トリガー関数テンプレートを選択
デプロイは以下。
- Azure へのサインイン
- Visual Studio Code で F1 キーを押してコマンド パレットを開き、コマンド Azure Functions: Deploy to Fanction App を選択します。
LINE側の設定
- Line Developers コンソール -> プロバイダ -> 作ったプロバイダ名 -> Messaging API設定 -> Webhook URLに、以下を設定する。
azure -> ホーム -> 作った関数アプリ -> コードとテスト -> 関数の URL を取得 -> default (ホスト キー)
- Webhookの利用は、有効にする
- 応答メッセージは、無効にする。
azure functions側の設定
関数アプリ -> 設定 -> 環境変数に、以下の2つを定義する。
- LINE_CHANNEL_ACCESS_TOKEN
- LINE_USER_ID
LINE_CHANNEL_ACCESS_TOKENは、以下にある値
Line Developers コンソール -> プロバイダ -> 作ったプロバイダ名 -> チャネル基本設定 -> Messaging API設定 ->チャネルアクセストークン
LINE_USER_IDは、以下にある値
Line Developers コンソール -> プロバイダ -> 作ったプロバイダ名 -> チャネル基本設定 -> あなたのユーザーID
pythonのスクリプト
requirements.txt
loggingとosは記載不要。 local.settings.jsonにも記載するが、これらの設定は、関数をローカルで実行するときにのみ使用される。(今回は使っていない)
# DO NOT include azure-functions-worker in this file # The Python Worker is managed by Azure Functions platform # Manually managing azure-functions-worker may cause unexpected issues azure-functions requests
function_app.py
import azure.functions as func import logging import requests import os app = func.FunctionApp(http_auth_level=func.AuthLevel.FUNCTION) LINE_CHANNEL_ACCESS_TOKEN = os.getenv('LINE_CHANNEL_ACCESS_TOKEN',None) LINE_USER_ID = os.getenv('LINE_USER_ID',None) if not LINE_CHANNEL_ACCESS_TOKEN or not LINE_USER_ID: logging.error("環境変数 LINE_CHANNEL_ACCESS_TOKEN または LINE_USER_ID が設定されていません。") raise EnvironmentError("必要な環境変数が設定されていません。") @app.route(route="http_trigger_line") def http_trigger_line(req: func.HttpRequest) -> func.HttpResponse: return echo_back(req) def send_reply(reply_token: str, message: str): logging.info('send_reply triggered.') reply_url = "https://api.line.me/v2/bot/message/reply" headers = { "Content-Type": "application/json", "Authorization": f"Bearer {LINE_CHANNEL_ACCESS_TOKEN}" } data = { "replyToken": reply_token, "messages": [ {"type": "text", "text": message} ] } response = requests.post(reply_url, headers=headers, json=data) if response.status_code != 200: logging.error(f"Error sending reply: {response.status_code}, {response.text}") def echo_back(req: func.HttpRequest)-> func.HttpResponse: logging.info('echo back triggered.') try: # LINEからのリクエストボディを取得 body = req.get_json() events = body.get("events", []) ret=func.HttpResponse("OK", status_code=200) for event in events: if event.get("type") == "message": message_type = event["message"].get("type") user_message = event["message"].get("text") reply_token = event.get("replyToken") if message_type == "text": # 受信したメッセージをオウム返し reply_message = f"あなたのメッセージ: {user_message}" ret=send_reply(reply_token, reply_message) return ret except Exception as e: logging.error(f"Error processing request: {str(e)}") send_message(str(e)) return func.HttpResponse("Bad Request", status_code=400) def send_message (message: str)-> func.HttpResponse: logging.info('LINE push message triggered.') try: # LINE Push Message APIのエンドポイント push_url = "https://api.line.me/v2/bot/message/push" # HTTPヘッダー headers = { "Content-Type": "application/json", "Authorization": f"Bearer {LINE_CHANNEL_ACCESS_TOKEN}" } # 送信するメッセージのデータ data = { "to": LINE_USER_ID, "messages": [ { "type": "text", "text": "send_message:" + message } ] } # LINE APIにリクエストを送信 response = requests.post(push_url, headers=headers, json=data) if response.status_code == 200: logging.info("Message sent successfully.") return func.HttpResponse("Message sent successfully.", status_code=200) else: logging.error(f"Failed to send message: {response.status_code}, {response.text}") return func.HttpResponse(f"Failed to send message: {response.status_code}",response.status_code) except Exception as e: logging.error(f"Error processing request: {str(e)}") send_message(str(e)) return func.HttpResponse("Bad Request", status_code=400)
プロンプトの管理ツール
記述の多いプロンプトを使いやすくするためのツール。AIに聞きながら作成しました。
マークダウンでプロンプトのテンプレートを用意しておき、具体的な部分は変数に埋め込みプロンプトを組み立てます。

生成されたプロンプト
元のテンプレートにあった変数が、GUIの記載内容で上書きされている。
# STEP1
[原文]の内容を要約して。
### 原文
はてなブログは、あなたの思いや考えを残したり、
さまざまな人が綴った多様な価値観に触れたりできる場所です。# STEP2
[原文]の内容を要約したドラフトが、[レビュー対象]です。
[レビュー対象]に、[原文]の内容から抜け落ちた部分がないか確認して。
### 対象
はてなブログは、あなたの思いや考えを残したり、
さまざまな人が綴った多様な価値観に触れたりできる場所です。### レビュー対象
未入力
プログラム
import tkinter as tk from tkinter import ttk, scrolledtext, messagebox import os import re import time from dotenv import load_dotenv load_dotenv() # Load environment variables from .env file class MarkdownEditorApp: def __init__(self, root): self.root = root self.root.title("プロンプト管理ツール") # 変数の初期化 self.selected_file_path = "" self.variables = [] self.entries = {} self.current_step = 0 self.max_step = 0 # Notebookウィジェットを作成 self.notebook = ttk.Notebook(root) self.notebook.pack(expand=True, fill='both') # タブ1 - 設定 self.tab1 = ttk.Frame(self.notebook) self.notebook.add(self.tab1, text='テンプレート選択') # 左の列 - ディレクトリ構造のツリービュー self.tree = ttk.Treeview(self.tab1) self.tree.grid(row=0, column=0, sticky='nsew') # 中央の列 - mdファイルの一覧表示 self.md_listbox = tk.Listbox(self.tab1) self.md_listbox.grid(row=0, column=1, sticky='nsew') # 右の列 - mdファイルの内容表示 self.file_content_text = scrolledtext.ScrolledText(self.tab1, wrap=tk.WORD) self.file_content_text.grid(row=0, column=2, sticky='nsew') # グリッド構造の設定 self.tab1.grid_columnconfigure(0, weight=1, uniform="column") self.tab1.grid_columnconfigure(1, weight=1, uniform="column") self.tab1.grid_columnconfigure(2, weight=2, uniform="column") self.tab1.grid_rowconfigure(0, weight=1) # ディレクトリ構造の表示 self.current_directory = os.getenv("MYDIRECTORY") # ここに表示したいディレクトリを指定 self.selected_path = self.current_directory self.root_node = self.tree.insert('', 'end', text=self.current_directory) self.tree.item(self.root_node, open=True) self.populate_treeview(self.root_node, self.current_directory) # ツリービューのイベント self.tree.bind("<ButtonRelease-1>", self.on_tree_click) # mdファイル一覧の選択イベント self.md_listbox.bind('<<ListboxSelect>>', self.on_md_select) # タブ2 - 生成 self.tab2 = ttk.Frame(self.notebook) self.notebook.add(self.tab2, text='変数入力とプロンプト生成') # 左の列 - 説明のラベルとテキストボックス self.variables_frame = ttk.Frame(self.tab2, relief="solid", borderwidth=1) self.variables_frame.grid(row=0, column=0, padx=5, pady=5, sticky='nsew') # 右の列 - ボタンとプロンプト self.buttons_frame = ttk.Frame(self.tab2, relief="solid", borderwidth=1) self.buttons_frame.grid(row=0, column=1, padx=5, pady=5, sticky='nsew') # 各ボタンを同じ行に配置 self.update_button = ttk.Button(self.buttons_frame, text="生成/更新", command=self.generate_prompt) self.update_button.grid(row=0, column=0, padx=5, pady=5, sticky='ew') self.prev_button = ttk.Button(self.buttons_frame, text="前のステップ", command=self.prev_step) self.prev_button.grid(row=0, column=1, padx=5, pady=5, sticky='ew') self.next_button = ttk.Button(self.buttons_frame, text="次のステップ", command=self.next_step) self.next_button.grid(row=0, column=2, padx=5, pady=5, sticky='ew') self.copy_button = ttk.Button(self.buttons_frame, text="コピー", command=self.copy_to_clipboard) self.copy_button.grid(row=0, column=3, padx=5, pady=5, sticky='ew') # self.current_stepの値を表示するラベルをボタンの右側に配置 self.step_label = ttk.Label(self.buttons_frame, text=f"現在のステップ: {self.current_step}") self.step_label.grid(row=0, column=4, padx=5, pady=5, sticky='ew') # テキストボックスをbuttons_frame内に配置し、残りのすべての行を使用 self.prompt_text_box = scrolledtext.ScrolledText(self.buttons_frame, height=10, wrap=tk.WORD) self.prompt_text_box.grid(row=1, column=0, columnspan=5, padx=5, pady=5, sticky='nsew', rowspan=100) # グリッド構造の設定 self.tab2.grid_columnconfigure(0, weight=1,uniform="column") # self.variables_frame の列 self.tab2.grid_columnconfigure(1, weight=1,uniform="column") # self.buttons_frame の列 # ボタンの行の高さを固定し、幅は拡大 self.buttons_frame.grid_rowconfigure(0, weight=0) # ボタンとラベルの行 # テキストボックスの行のリサイズ設定 self.buttons_frame.grid_rowconfigure(1, weight=1) # 2行目以降の行にテキストボックスを表示 def populate_treeview(self, parent, path): for item in os.listdir(path): full_path = os.path.join(path, item) if os.path.isdir(full_path): node = self.tree.insert(parent, 'end', text=item) self.populate_treeview(node, full_path) def on_tree_click(self, event): selected_item = self.tree.selection()[0] self.selected_path = os.path.join(self.current_directory, self.tree.item(selected_item, "text")) self.list_md_files(self.selected_path) def list_md_files(self, directory): self.md_listbox.delete(0, tk.END) for item in os.listdir(directory): if item.endswith('.md'): self.md_listbox.insert(tk.END, item) def on_md_select(self, event): selected_file = self.md_listbox.get(self.md_listbox.curselection()) self.selected_file_path = os.path.join(self.selected_path, selected_file) self.load_md_content() def load_md_content(self): with open(self.selected_file_path, 'r', encoding="utf-8") as file: content = file.read() self.file_content_text.delete(1.0, tk.END) self.file_content_text.insert(tk.END, content) # タブ2のラベルとテキストボックスを更新 self.update_variables(content) self.detect_steps(content) def update_variables(self, content): # 前の入力フィールドを削除 for widget in self.variables_frame.winfo_children(): widget.destroy() # 変数の検出 self.variables = re.findall(r'\{([^:}]+):([^}]+)\}', content) seen_variables = set() self.entries = {} for var_name, var_desc in self.variables: if var_name not in seen_variables: seen_variables.add(var_name) label = ttk.Label(self.variables_frame, text=var_desc) label.grid(sticky="w", padx=5, pady=2) entry = tk.Text(self.variables_frame, height=3) entry.grid(sticky="ew", padx=5, pady=2) self.entries[var_name] = entry self.variables_frame.grid_rowconfigure(len(self.entries), weight=1) def detect_steps(self, content): # ステップの検出 self.steps = re.findall(r'# *STEP *(\d+)', content) self.steps = sorted(set(int(step) for step in self.steps)) self.max_step = len(self.steps) def generate_prompt(self): if not self.selected_file_path: messagebox.showwarning("警告", "mdファイルが選択されていません。") return # テキストボックスに入力された内容を取得 context = {var_name: entry.get("1.0", tk.END).strip() for var_name, entry in self.entries.items()} with open(self.selected_file_path, 'r', encoding='utf-8') as file: content = file.read() # 変数をテキストボックスの内容に置き換える result = content for var_name, var_value in context.items(): result = re.sub(r'\{' + var_name + r':[^\}]+\}', re.escape(var_value), result) # バックスラッシュでエスケープされた正規表現の文字を元に戻す result=self.unescape_re_escaped_string(result) # 結果をプロンプトテキストボックスに表示 if self.current_step == 0: self.prompt_text_box.delete(1.0, tk.END) self.prompt_text_box.insert(tk.END, result) else: self.show_step_content(result) def show_step_content(self, content): # ステップに応じた内容を表示 if self.current_step == 1: step_pattern = r'# *STEP *1' else: step_pattern = rf'# *STEP *{self.current_step}' next_step_pattern = rf'# *STEP *{self.current_step + 1}' start = re.search(step_pattern, content) if start: start_index = start.end() else: start_index = 0 end = re.search(next_step_pattern, content) if end: end_index = end.start() else: end_index = len(content) step_content = content[start_index:end_index].strip() self.prompt_text_box.delete(1.0, tk.END) self.prompt_text_box.insert(tk.END, step_content) def next_step(self): if self.current_step < self.max_step: self.current_step += 1 self.generate_prompt() self.update_step_label() def prev_step(self): if self.current_step > 0: self.current_step -= 1 self.generate_prompt() self.update_step_label() def update_step_label(self): self.step_label.config(text=f"現在のステップ: {self.current_step}") def copy_to_clipboard(self): content = self.prompt_text_box.get("1.0", tk.END).strip() self.root.clipboard_clear() self.root.clipboard_append(content) messagebox.showinfo("コピー", "プロンプトがクリップボードにコピーされました。") def unescape_re_escaped_string(self, escaped_string): # バックスラッシュでエスケープされた正規表現の文字を元に戻す unescaped_string = re.sub(r'\\(.)', r'\1', escaped_string) # エスケープされた改行を元に戻す unescaped_string = unescaped_string.replace('\\\n', '\n') # 残ったバックスラッシュとスペースをスペースに置換 unescaped_string = unescaped_string.replace('\\ ', ' ') return unescaped_string if __name__ == "__main__": root = tk.Tk() app = MarkdownEditorApp(root) root.mainloop()
プロンプトのテンプレート
マークダウンとして記述。
プロンプトに複数回質問することを想定して、「#STEP(\d)」で区切り。
変数として、{val1:要約対象}や{val2:要約のドラフト}などを設定可能。val1やval2が変数名、コロンの後の「要約対象」はユーザ向けの説明。
# STEP1
[原文]の内容を要約して。
### 原文
{val1:要約対象}
# STEP2
[原文]の内容を要約したドラフトが、[レビュー対象]です。
[レビュー対象]に、[原文]の内容から抜け落ちた部分がないか確認して。
### 対象
{val1:要約対象}
### レビュー対象
{val2:要約のドラフト}
制約事項
- ウィンドウサイズを変更しても、テキストボックスの縦幅が変わらない。
- 変数として入力された内容がエスケープされる。一応戻しているが、失敗しているケースがある。
Azure音声サービス テキストを音声に変換
Azure音声サービスをつかったテキストを音声(MP3)に変換
Azureの音声サービスを利用して、テキストを音声に変換するプログラム。Text2Speechのカテゴリ。 単純なテキストではなく、SSML(音声合成マークアップ言語 Speech Synthesis Markup Language)で指定。
Azure音声サービスは無料枠もありますが有料です。100万文字あたり15$だそうです。
長すぎるSSMLは変換に失敗します。別途バッチAPIを利用するプログラムで変換するか、短いSSMLで作成し、できた音声ファイルをローカルで結合してください。
プログラム
import azure.cognitiveservices.speech as speechsdk from dotenv import load_dotenv # python-dotenv import os import logging # ログの設定 logging.basicConfig(level=logging.INFO) # .envファイルから環境変数を読み込む load_dotenv() def ssml_to_speech(ssml, output_filename): speech_key = os.getenv("SPEECH_KEY") service_region = os.getenv("SPEECH_REGION") # 環境変数が設定されているかチェック if not speech_key or not service_region: logging.error("Environment variables for SPEECH_KEY and SPEECH_REGION must be set.") raise ValueError("Missing environment variables for SPEECH_KEY or SPEECH_REGION") speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) audio_config = speechsdk.audio.AudioOutputConfig(filename=output_filename) speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" speech_config.set_speech_synthesis_output_format(speechsdk.SpeechSynthesisOutputFormat.Audio24Khz48KBitRateMonoMp3) synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config) result = synthesizer.speak_ssml_async(ssml).get() if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted: logging.info(f"Speech synthesized to [{output_filename}]") elif result.reason == speechsdk.ResultReason.Canceled: cancellation_details = result.cancellation_details logging.error(f"Speech synthesis canceled: {cancellation_details.reason}") if cancellation_details.reason == speechsdk.CancellationReason.Error: logging.error(f"Error details: {cancellation_details.error_details}") def read_ssml_file(ssml_file_path): """SSMLファイルの内容を読み込む関数""" with open(ssml_file_path, 'r', encoding='utf-8') as file: return file.read() def generate(ssml_file_path): # SSMLファイルと出力ファイルの指定 output_filename = os.path.splitext(ssml_file_path)[0] + ".mp3" # SSMLファイルの内容を読み込む ssml_content = read_ssml_file(ssml_file_path) # SSMLを音声に変換 ssml_to_speech(ssml_content, output_filename) if __name__ == '__main__': generate(r"変換テスト.xml")
.envファイル
Azure AI services 音声サービスの、キーとリージョンの情報を環境変数に設定することで、スクリプト内での記述を隠蔽しています。 プログラムではSPEECH_KEYとSPEECH_REGIONの2つを利用しています。


変換テスト.xml
BOMありUTF-8という記載があったが、BOMなしUTF-8で通っている。
<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='ja-JP'> <voice name='ja-JP-NanamiNeural'> その虹には7つの色があります。 </voice> <voice name="en-US-JennyNeural"> The rainbow has seven colors. </voice> </speak>
シーケンシャルなデータに対して、固定のウィンドウ幅での演算を支援する関数
シーケンシャルなデータに対して、固定のウィンドウ幅での演算を支援する関数。mymap()。
指定されたウィンドウ幅でスライスして実際の演算関数に渡す。
シーケンシャルなデータは、1つまたは2つ。将来は可変長引数にしてもよいかもしれない。
コード
def mymap(function_name, window_size, list1, list2=None): len_ret =len(list1) ret = [None]*len_ret assert window_size > 0,"window_size > 0" assert type(window_size) is int , "window_size type must be int" if list2 is not None: assert len_ret == len(list2) if list2 is None: for i in range(window_size-1, len_ret):#長さ5の時、iの最大は4まで。 # iはretの添え字 tmp_list1=list1[i-window_size+1:i+1] #スライスの時、末尾:xのlist1[x]の値は含まれない。 ret[i]=function_name(tmp_list1) else: for i in range(window_size-1, len_ret): tmp_list1=list1[i-window_size+1:i+1] tmp_list2=list2[i-window_size+1:i+1] ret[i]=function_name(tmp_list1,tmp_list2) return ret def myaverage(list1): return sum(list1)/len(list1) def myadd(list1): return sum(list1) def mymultadd(list1,list2): m=0 for i in range(len(list1)): #print(list1[i] , "*",list2[i]) m= m + list1[i] * list2[i] return m def myEuclid(list1,list2): m=0 for i in range(len(list1)): m = m + (list1[i] - list2[i])**2 return m if __name__ == '__main__': list1=[1,2,3,4,5] list2=[0,0,0,0,0] ret = mymap(myadd,1,list1) print(ret) ret = mymap(myadd,2,list1) print(ret) ret = mymap(myadd,3,list1) print(ret) ret = mymap(myadd,4,list1) print(ret) ret = mymap(myadd,5,list1) print(ret) ret = mymap(mymultadd,3,list1,list2) print(ret) ret = mymap(myEuclid,1,list1,list2) print(ret)
実行結果
[1, 2, 3, 4, 5] [None, 3, 5, 7, 9] [None, None, 6, 9, 12] [None, None, None, 10, 14] [None, None, None, None, 15] [None, None, 0, 0, 0] [1, 4, 9, 16, 25]
回帰直線を書いてみた
コード
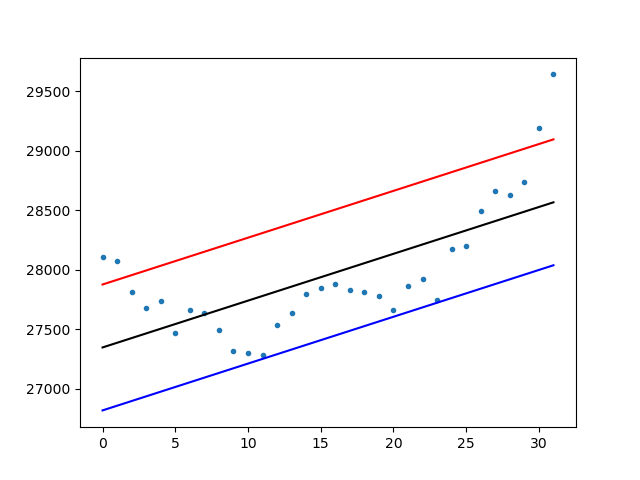
import numpy as np import matplotlib.pyplot as plt x = list(range(0,31+1)) y = [28105,28070,27815,27680,27740,27470,27665,27635,27495,27315,27300,27285,27535,27635,27800,27845,27880,27830,27815,27775,27665,27865,27925,27745,28175,28195,28490,28660,28630,28735,29190,29640] # フィッティング a, b = np.polyfit(x, y, 1) sv = np.std(y) print(f"傾き={a}, 切片={b}, 標準偏差={sv}") nx = np.array(x) f=nx*a+b # 1σ fps=f+sv fms=f-sv plt.plot(x, y, '.', x,f,'k-',x,fps,'r-',x,fms,'b-') plt.show()
結果
傾き=39.3154325513205, 切片=27347.01704545453, 標準偏差=528.5907478484063
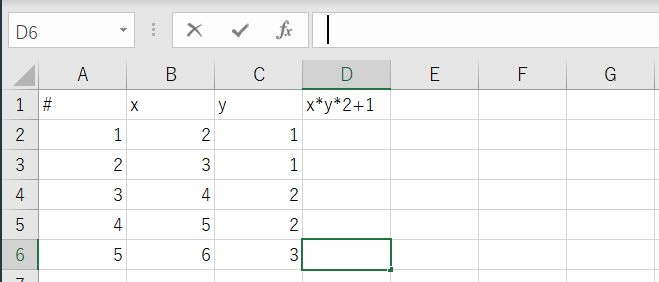
pythonでxlsファイルの数式をコピー(フィル)。
やりたいこと
pythonでxlsファイルの数式をコピー(フィル)。
相対参照や絶対参照ありで、参照関係をきちんと維持したままで。
コード
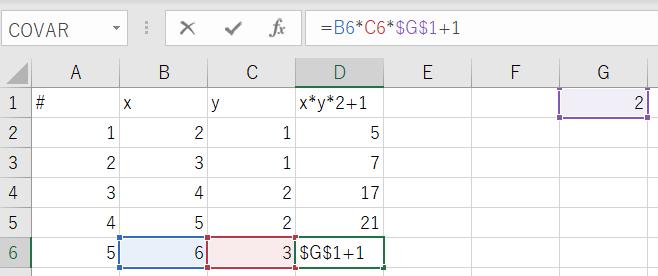
from openpyxl import load_workbook from openpyxl.formula.translate import Translator from openpyxl.utils.cell import coordinate_to_tuple wb = load_workbook('translator.xlsx') ws = wb["Sheet1"] #絶対参照させる場所に値を設定 ws['G1'].value = 2 # 数式と、数式を埋め込む一番上のセルを指定。 origin_formula='=B2*C2*$G$1+1' origin_cell="D2" (origin_row, origin_col)= coordinate_to_tuple(origin_cell) # originの列、2行目から一番したまで数式をフィル # origin Cellに数式をあらかじめ埋めておく必要はない。 for row in ws.iter_rows(min_row=2, max_row=ws.max_row, min_col=origin_col, max_col=origin_col): ws[row[0].coordinate]= Translator(origin_formula,origin=origin_cell).translate_formula(row[0].coordinate) #print(ws[row[0].coordinate].value) wb.save('translator_done.xlsx')
結果
月の第n曜日とか、月の最終曜日かどうかの判定
その月の第n曜日の計算と、月の最終曜日の判定関数。
指定の日付に対して、第N曜日の計算は単純に日付だけ。
逆に最終曜日の判定はちょっと面倒。
コード
import datetime def nth_weekday(target_date : datetime.date): target_date_day=target_date.day if target_date_day <=7: return 1 elif target_date_day <=14: return 2 elif target_date_day <=21: return 3 elif target_date_day <=28: return 4 else: return 5 def is_last_weekday(target_date : datetime.date): this_month=target_date.month tmp_date = target_date + datetime.timedelta(days=7) tmp_month = tmp_date.month if this_month != tmp_month: return True else: return False target_date=datetime.date(2021,1,1) datetime.timedelta(days=1) for i in range(366): print(target_date,nth_weekday(target_date),is_last_weekday(target_date)) target_date= target_date+ datetime.timedelta(days=1)