シーケンシャルなデータに対して、固定のウィンドウ幅での演算を支援する関数
シーケンシャルなデータに対して、固定のウィンドウ幅での演算を支援する関数。mymap()。
指定されたウィンドウ幅でスライスして実際の演算関数に渡す。
シーケンシャルなデータは、1つまたは2つ。将来は可変長引数にしてもよいかもしれない。
コード
def mymap(function_name, window_size, list1, list2=None): len_ret =len(list1) ret = [None]*len_ret assert window_size > 0,"window_size > 0" assert type(window_size) is int , "window_size type must be int" if list2 is not None: assert len_ret == len(list2) if list2 is None: for i in range(window_size-1, len_ret):#長さ5の時、iの最大は4まで。 # iはretの添え字 tmp_list1=list1[i-window_size+1:i+1] #スライスの時、末尾:xのlist1[x]の値は含まれない。 ret[i]=function_name(tmp_list1) else: for i in range(window_size-1, len_ret): tmp_list1=list1[i-window_size+1:i+1] tmp_list2=list2[i-window_size+1:i+1] ret[i]=function_name(tmp_list1,tmp_list2) return ret def myaverage(list1): return sum(list1)/len(list1) def myadd(list1): return sum(list1) def mymultadd(list1,list2): m=0 for i in range(len(list1)): #print(list1[i] , "*",list2[i]) m= m + list1[i] * list2[i] return m def myEuclid(list1,list2): m=0 for i in range(len(list1)): m = m + (list1[i] - list2[i])**2 return m if __name__ == '__main__': list1=[1,2,3,4,5] list2=[0,0,0,0,0] ret = mymap(myadd,1,list1) print(ret) ret = mymap(myadd,2,list1) print(ret) ret = mymap(myadd,3,list1) print(ret) ret = mymap(myadd,4,list1) print(ret) ret = mymap(myadd,5,list1) print(ret) ret = mymap(mymultadd,3,list1,list2) print(ret) ret = mymap(myEuclid,1,list1,list2) print(ret)
実行結果
[1, 2, 3, 4, 5] [None, 3, 5, 7, 9] [None, None, 6, 9, 12] [None, None, None, 10, 14] [None, None, None, None, 15] [None, None, 0, 0, 0] [1, 4, 9, 16, 25]
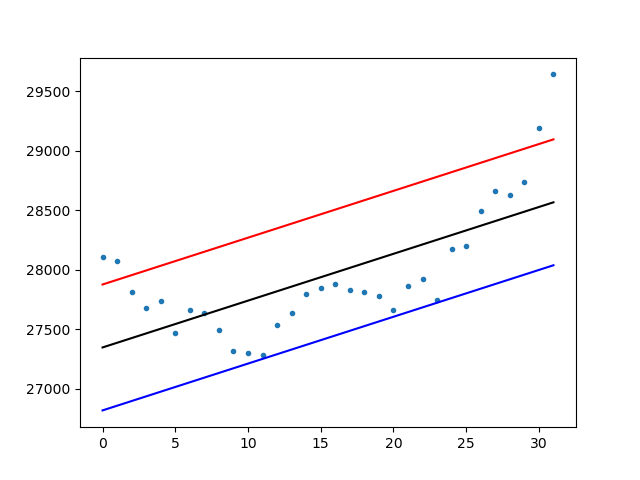
回帰直線を書いてみた
コード
import numpy as np import matplotlib.pyplot as plt x = list(range(0,31+1)) y = [28105,28070,27815,27680,27740,27470,27665,27635,27495,27315,27300,27285,27535,27635,27800,27845,27880,27830,27815,27775,27665,27865,27925,27745,28175,28195,28490,28660,28630,28735,29190,29640] # フィッティング a, b = np.polyfit(x, y, 1) sv = np.std(y) print(f"傾き={a}, 切片={b}, 標準偏差={sv}") nx = np.array(x) f=nx*a+b # 1σ fps=f+sv fms=f-sv plt.plot(x, y, '.', x,f,'k-',x,fps,'r-',x,fms,'b-') plt.show()
結果
傾き=39.3154325513205, 切片=27347.01704545453, 標準偏差=528.5907478484063
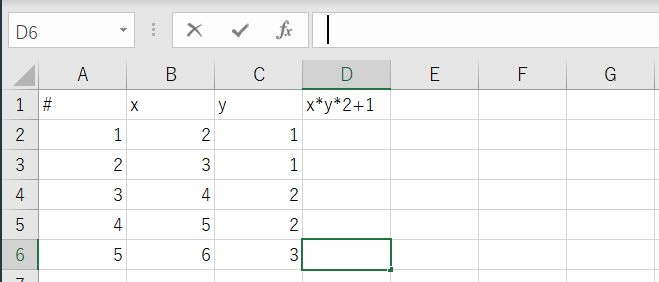
pythonでxlsファイルの数式をコピー(フィル)。
やりたいこと
pythonでxlsファイルの数式をコピー(フィル)。
相対参照や絶対参照ありで、参照関係をきちんと維持したままで。
コード
from openpyxl import load_workbook from openpyxl.formula.translate import Translator from openpyxl.utils.cell import coordinate_to_tuple wb = load_workbook('translator.xlsx') ws = wb["Sheet1"] #絶対参照させる場所に値を設定 ws['G1'].value = 2 # 数式と、数式を埋め込む一番上のセルを指定。 origin_formula='=B2*C2*$G$1+1' origin_cell="D2" (origin_row, origin_col)= coordinate_to_tuple(origin_cell) # originの列、2行目から一番したまで数式をフィル # origin Cellに数式をあらかじめ埋めておく必要はない。 for row in ws.iter_rows(min_row=2, max_row=ws.max_row, min_col=origin_col, max_col=origin_col): ws[row[0].coordinate]= Translator(origin_formula,origin=origin_cell).translate_formula(row[0].coordinate) #print(ws[row[0].coordinate].value) wb.save('translator_done.xlsx')
結果
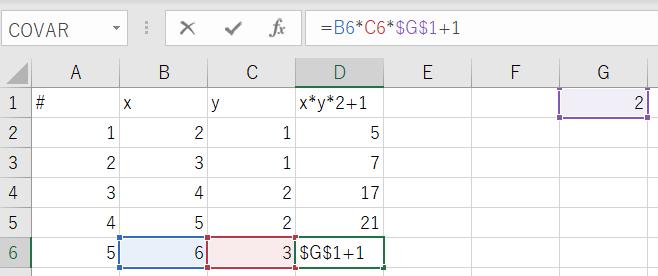
月の第n曜日とか、月の最終曜日かどうかの判定
その月の第n曜日の計算と、月の最終曜日の判定関数。
指定の日付に対して、第N曜日の計算は単純に日付だけ。
逆に最終曜日の判定はちょっと面倒。
コード
import datetime def nth_weekday(target_date : datetime.date): target_date_day=target_date.day if target_date_day <=7: return 1 elif target_date_day <=14: return 2 elif target_date_day <=21: return 3 elif target_date_day <=28: return 4 else: return 5 def is_last_weekday(target_date : datetime.date): this_month=target_date.month tmp_date = target_date + datetime.timedelta(days=7) tmp_month = tmp_date.month if this_month != tmp_month: return True else: return False target_date=datetime.date(2021,1,1) datetime.timedelta(days=1) for i in range(366): print(target_date,nth_weekday(target_date),is_last_weekday(target_date)) target_date= target_date+ datetime.timedelta(days=1)
記述のカテゴリ分け
もとの詳細な記述を分析して、下位のカテゴリに分類し、下位のカテゴリをさらに上位カテゴリに再分類する。
2階層のブレイクダウンの逆。
ルールは辞書で作成。keyにあたる部分がカテゴリ名、valueにはlistを設定する。
そのリストにある記述が、もとの詳細な記述の中にあれば、そのカテゴリであると判断する。
下位カテゴリが複数のカテゴリに該当する場合、もとの詳細な記述の最初に書いてあるカテゴリとする。
結果の見方は、「もとの詳細な記述 下位カテゴリ 上位カテゴリ」
結果
AA123 A1 A AA123B22 A1 A B22AA123 B2 B asdf None None asC12df C1 None
ソース
def classify_category(source_descripton,rule_dic): category_found = False found_key= "" find_pos=100 # 十分な長さ for category_key in rule_dic.keys(): for category_value in rule_dic[category_key]: if category_value in source_descripton: category_found = True tmp_pos=source_descripton.find(category_value) if tmp_pos < find_pos: found_key = category_key find_pos=tmp_pos if category_found is False: found_key="None" return found_key if __name__ == '__main__': top_category={} second_category={} top_category["A"]=["A1","A2"] top_category["B"]=["B1","B2"] second_category["A1"]=["A11","A12"] second_category["A2"]=["A21","A22"] second_category["B1"]=["B11","B12"] second_category["B2"]=["B21","B22"] second_category["C1"]=["C11","C12"] source_descripton="AA123" second_category_description = classify_category(source_descripton,second_category) top_category_description = classify_category(second_category_description,top_category) print(source_descripton,second_category_description,top_category_description) source_descripton="AA123B22" second_category_description = classify_category(source_descripton,second_category) top_category_description = classify_category(second_category_description,top_category) print(source_descripton,second_category_description,top_category_description) source_descripton="B22AA123" second_category_description = classify_category(source_descripton,second_category) top_category_description = classify_category(second_category_description,top_category) print(source_descripton,second_category_description,top_category_description) source_descripton="asdf" second_category_description = classify_category(source_descripton,second_category) top_category_description = classify_category(second_category_description,top_category) print(source_descripton,second_category_description,top_category_description) source_descripton="asC12df" second_category_description = classify_category(source_descripton,second_category) top_category_description = classify_category(second_category_description,top_category) print(source_descripton,second_category_description,top_category_description)
3次元の表
多次元(3次元)の配列が必要になったので、初期化と参照の方法を確認。
2次元表の中の1枠をcellとみなして、cellの中にも1次元の配列があるイメージ。
コード
import itertools print("3次元の配列") dim_row =2 # row dim_col =3 # col dim_cell =4 # cell # ゼロ初期化 list_3d =[[[0 for z in range(dim_cell)] for y in range(dim_col)] for x in range(dim_row)] print("\nlist_3d[0][1][2]=1") list_3d[0][1][2]=1 print("\n単純にprint") print(list_3d) print("\n行を取り出してprint") for i in list_3d: print(i) print("\n行を、フラットな配列に変換") for i in list_3d: print(list(itertools.chain.from_iterable(i)))
実行結果
3次元の配列 list_3d[0][1][2]=1 単純にprint [[[0, 0, 0, 0], [0, 0, 1, 0], [0, 0, 0, 0]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]] 行を取り出してprint [[0, 0, 0, 0], [0, 0, 1, 0], [0, 0, 0, 0]] [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]] 行を、フラットな配列に変換 [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0] [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
コンソールの同じ行にprint
コンソールで、表示を更新したいけど、行は増やしたくないときに使うもの。
消してもよい情報をprintするときは、printt.printt("hoge","piyo1",over_write=True) のように、"over_write=True” とする。
実行結果
('hoge', 'piyo0')
('hoge', 'piyo3')
('hoge', 'piyo4')
('hoge', 'piyo7')
('hoge', 'piyo9')
コード
import time class printt(): # クラス変数 last_over_write_status = False @classmethod def printt(cls, *args, over_write=False): if __class__.last_over_write_status is True: print("\r",end="") else: pass if over_write is False: if __class__.last_over_write_status is True: # 1行前の表示残りを上書きするため、後半に空白を追加 print(args," ") else: print(args) __class__.last_over_write_status = False else: print(args,end="") __class__.last_over_write_status = True if __name__ =="__main__": printt.printt("hoge","piyo0") time.sleep(1) printt.printt("hoge","piyo1",over_write=True) time.sleep(1) printt.printt("hoge","piyo2",over_write=True) time.sleep(1) printt.printt("hoge","piyo3") time.sleep(1) printt.printt("hoge","piyo4") time.sleep(1) printt.printt("hoge","piyo5",over_write=True) time.sleep(1) printt.printt("hoge","piyo6",over_write=True) time.sleep(1) printt.printt("hoge","piyo7") time.sleep(1) printt.printt("hoge","piyo8",over_write=True) time.sleep(1) printt.printt("hoge","piyo9")