openpyxlで、エクセルファイルのフィルタの設定をする
openpyxlで、エクセルファイルのフィルタの設定をする実証コード
エクセルで開いても、フィルタの設定は入っているが、フィルタ表示はされていない状態で表示される。
エクセルで開いて、フィルタのプルダウンを開いて、再適用すれば、フィルタリングされた状態で表示される。
コード
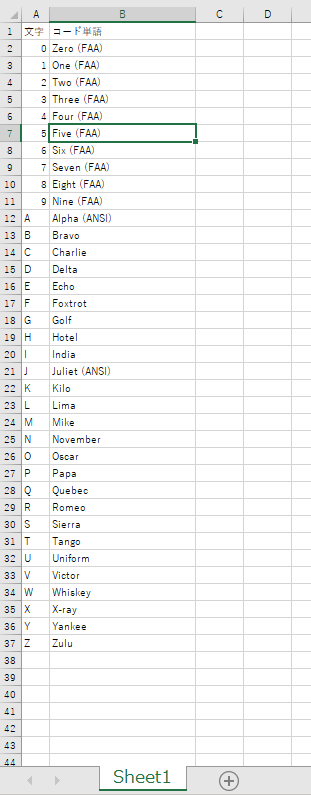
from openpyxl import Workbook, load_workbook, utils # 1行目がヘッダで、A2からデータが入っている想定 read_filename = r"C:\dev\SampleCodes\hello_openpyxl\NATO_phonetic_alphabet.xlsx" save_filename = read_filename.replace(".xlsx", "_filterd.xlsx") wb = load_workbook(read_filename) # 対象シートは 'Sheet1' ws = wb['Sheet1'] # フィルタを設定したい列名を指定 filter_col = 'A' # column_index_from_string(A)は1を返すが、使うときはオフセットで0始まりなので1を引いておく。 filter_col_offset = utils.column_index_from_string(filter_col) - 1 print("filter_col = {0}, filter_col_offset = {1}".format( filter_col, filter_col_offset)) # 表示したい行にある、A列の内容 # 実際にはない値を指定しても、add_filter_columnでは無視される。 filter_words = ["0", "A", "Z"] # データがある最大行を取得 max_row = ws.max_row max_col = ws.max_column print("max_row = {0}, max_col = {1}".format(max_row, max_col)) # 表示したい値が、実際にあるか確かめておく for word in filter_words: flag_find = False for row_index in range(0, max_row): cell_value = ws.cell( row=row_index+1, column=utils.column_index_from_string(filter_col)).value if word == str(cell_value): flag_find = True print("{0} in filter_words found".format(word)) break if flag_find == False: print("Error!! {0} in filter_words not found".format(word)) exit(-1) # 列番号をxlsの列名アルファベットに変換 max_col_letter = utils.cell.get_column_letter(max_col) # filterの範囲を指定 # A列からデータがあることが前提。 ws.auto_filter.ref = "A1:" + max_col_letter + str(max_row) print("ws.auto_filter.ref = {0}".format(ws.auto_filter.ref)) # filter指定 # filter_col_index は 0だと、ws.auto_filter.refの範囲で、いちばん左の列 ws.auto_filter.add_filter_column(filter_col_offset, filter_words) # サンプルコードにあったソートはしなくてよい。 # https://openpyxl.readthedocs.io/en/latest/filters.html#using-filters-and-sorts # ws.auto_filter.add_sort_condition("B2:B15") # 保存はする。 # エクセルで開いても、フィルタの設定は入っているが、フィルタ表示はされていない状態で表示される。 # エクセルで開いて、フィルタのプルダウンを開いて、再適用すれば、フィルタ表示される。 wb.save(save_filename) wb.close()
実行結果
(base) C:\dev\SampleCodes\hello_openpyxl>python hello_filter.py filter_col = A, filter_col_offset = 0 max_row = 37, max_col = 2 0 in filter_words found A in filter_words found Z in filter_words found ws.auto_filter.ref = A1:B37 (base) C:\dev\SampleCodes\hello_openpyxl>
順位を教えてくれる関数
順位を教えてくれる関数。
データ件数に対してn^2で計算時間がかかるようなので、大きな配列への適用は難しい。
自前環境での計算時間は大体以下の通り。
# 10000個で、0.2秒
# 20000個で、0.7秒
# 30000個で、1.5秒
# 40000個で、2.7秒
プログラム
import numpy as np import random import time # 1次元配列を渡したら、その配列の中での大きい順(一番大きな値に対しては1)を返してくれる関数。 # # 10000個で、0.2秒 # 20000個で、0.7秒 # 30000個で、1.5秒 # 40000個で、2.7秒 def calc_rank(data): np_data = np.array(data) rank = [None]*len(data) for index, value in enumerate(data): rank[index] = np.sum(np_data >= value) return rank def rand_list(length): rl = [None]*length for index in range(length): rl[index] = random.randrange(0, length*2) return rl if __name__ == "__main__": # data=[0,12,53,9,31,78,40,87,84,55,20,77] length = 1000 data = rand_list(length) tic = time.time() rank = calc_rank(data) toc = time.time() print("データ件数", length) print("計算時間(秒)", toc-tic) print("計算結果抜粋") for i in range(len(data)): print("{0} {1}".format(data[i], rank[i])) if i > 5: break # 印字は邪魔なので適当にbreak
実行結果
データ件数 12 計算時間(秒) 0.0 計算結果抜粋 0 12 12 10 53 6 9 11 31 8 78 3 40 7 87 1 84 2 55 5 20 9 77 4
Cisco スイッチコマンド備忘録
gwがスイッチの名前です。
Terminal(CUI関係)
terminal length 0
--More-- が出てくるときに。0にすれば全部一括で表示される。行数を指定できる。
DHCP関連
DHCPのリリース状況確認
show ip dhcp binding
固定IPの割り当て
configure ip dhcp pool pool_sample import all host 192.168.11.2 255.255.255.0 hardware-address 0123.4567.89AB dns-server 192.168.1.1 client-name pool_sample default-router 192.168.1.1 lease infinite end
hardware-addressは、DHCPのリリース状況確認で確認できる。
hardware-addressは、client-identifier となることもある。その時は、01+MACアドレス、のような値になっている。
自動割り当てされたIPの解除(MAC重複解除)
clear ip dhcp binding 192.168.11.2
よく使うのは、hardware-address を割り当てようとして、以下が出てきたときなど。
% A binding for this client already exists.
アクセスリスト関係
WAN側のInerfaceに設定すべきアクセスリスト
https://blog.redbox.ne.jp/cisco-acl-cbac.html
アクセスリストの設置場所、方向の話
アクセスリストを理解する
現在の設定のエクスポート(USBメモリを刺した状態で)
customer-config という名前のファイルでUSBメモリに保存される。
copy running-config usbflash0:customer-config
リモートアクセスVPN
Ciscoの資料。ステップ18 [ハッシュ アルゴリズム MD5 を使用してパスワードを暗号化する]のチェックを解除 をしないとつながらない。
https://community.cisco.com/t5/cisco-start-%E3%83%89%E3%82%AD%E3%83%A5%E3%83%A1%E3%83%B3%E3%83%88/%E3%83%AA%E3%83%A2%E3%83%BC%E3%83%88-%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9-ipsec-vpn-%E3%82%92%E8%A8%AD%E5%AE%9A%E3%81%99%E3%82%8B/ta-p/3292247
リストの結合と、DBへの格納
長さが同じリストを、列が増える方向に連結して、DBに格納する検証コード。
Pandasを経由したほうが、SQLでのテーブル定義 をしなくてもよいから楽
プログラム
import pandas as pd import sqlite3 # 長さが同じListを、列が増える方向に連結 # Index は無しで、DBに入れる。 # ------------------------------------------- # 結合 x = [1, 2, 3, 4, 5] y = ['a', 'b', 'c', 'd', 'e'] z = [1.1, 2.2, 3.3, 4.4, 5.5] # name はDBの列名になる。 s_x = pd.Series(data=x, name="x") s_y = pd.Series(data=y) s_y.name = "y" s_z = pd.Series(data=z) # axis=0 行を増やす方向に連結 axis = 0 df1 = pd.concat([s_x, s_y], axis=axis) print(df1, type(df1)) # axis=1 列を増やす方向に連結 axis = 1 df1 = pd.concat([s_x, s_y], axis=axis) print(df1, type(df1)) df2 = pd.concat([s_x, s_y], axis=axis) print(df2, type(df2)) df3 = pd.concat([s_x, s_y, s_z], axis=axis) print(df3, type(df3)) # ------------------------------------------- # DB書き込み con = sqlite3.connect(":memory:") con.isolation_level = None # None で自動コミットモード cur = con.cursor() cur.execute('PRAGMA temp_store=MEMORY;') cur.execute('PRAGMA journal_mode=MEMORY;') # DBへの書き込み df3を書き込み。インデックスは無し。 table_name = 'test_table' df3.to_sql(name=table_name, con=con, index=False) # テーブル定義の確認 tmp = cur.execute("SELECT * FROM sqlite_master WHERE type='table'") print("# テーブル定義の確認") for row in tmp: print(row) # 書き込んだの内容の確認 tmp = cur.execute("SELECT * FROM {0}".format(table_name)) print("# テーブルの内容の確認") for row in tmp: print(row) con.close()
実行結果
(base) C:\>python C:\hello_pandas\hello_concat.py
0 1
1 2
2 3
3 4
4 5
0 a
1 b
2 c
3 d
4 e
dtype: object <class 'pandas.core.series.Series'>
x y
0 1 a
1 2 b
2 3 c
3 4 d
4 5 e <class 'pandas.core.frame.DataFrame'>
x y
0 1 a
1 2 b
2 3 c
3 4 d
4 5 e <class 'pandas.core.frame.DataFrame'>
x y 0
0 1 a 1.1
1 2 b 2.2
2 3 c 3.3
3 4 d 4.4
4 5 e 5.5 <class 'pandas.core.frame.DataFrame'>
# テーブル定義の確認
('table', 'test_table', 'test_table', 2, 'CREATE TABLE "test_table" (\n"x" INTEGER,\n "y" TEXT,\n "0" REAL\n)')
# テーブルの内容の確認
(1, 'a', 1.1)
(2, 'b', 2.2)
(3, 'c', 3.3)
(4, 'd', 4.4)
(5, 'e', 5.5)
Visual Stuido Code & Anaconda環境構築(その2)
vscodeでanacondaを使うと出るエラーの対策。a以下のコマンドを実行すると、対処できるかも。
conda init
エラーの内容
PS C:\dev> C:/Users/<ユーザー名>/Anaconda3/Scripts/activate
PS C:\dev> conda activate base
conda : 用語 'conda' は、コマンドレット、関数、スクリプト ファイル、または操作可能なプログラムの名前として認識されません。
名前が正しく記述されていることを確認し、パスが含まれている場合はそのパスが正しいことを確認してから、再試行してください。
発生場所 行:1 文字:1
+ conda activate base
+ ~~~~~
+ CategoryInfo : ObjectNotFound: (conda:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
移動平均(numpy.convolve利用)1次元
関連記事に乗せている2次元よりは1次元のほうが使い勝手がよさそうなので書き換え。
起点からwindowsizeの範囲で合計するだけではなくて、起点側を,ignoresize個を無視して合計するような形にしている。
np.convolveの2つ目の引数の割当たりかたが想像の逆なので、v=np.flip(v) で反転している。
ソースコード
import numpy as np def np_moving_sum(data_1d,windowsize=3,ignoresize=0): ''' 1次元のリスト or np.array ''' if data_1d is None: data_1d = [1,2,3,5,8,13,21,34,55,89] if type(data_1d) == np.ndarray: np_data_1d=data_1d elif type(data_1d) == list: np_data_1d=np.array(data_1d) # np_data_1d.shape は、(10,) answer = np.zeros(np_data_1d.shape) answer[:] = np.nan # vの長さが3の時 # v[0]=0 3番目にマッピングされる # v[1]=1 2番目にマッピングされる # v[2]=0 1番目にマッピングされる v = np.ones(windowsize) v[0:ignoresize]=0 v=np.flip(v) answer[: np_data_1d.shape[0] - windowsize + 1 ]=np.convolve(np_data_1d, v, mode = "valid") return answer def np_moving_average(data_1d,windowsize=3,ignoresize=0): return np_moving_sum(data_1d,windowsize,ignoresize)/(windowsize-ignoresize) if __name__ == "__main__": data_1d = [1,2,3,5,8,13,21,34,55,89] print(data_1d,'\n') print(np_moving_sum(data_1d=data_1d,windowsize=3,ignoresize=2)) print(np_moving_sum(data_1d=data_1d,windowsize=3,ignoresize=1)) print(np_moving_sum(data_1d=data_1d,windowsize=3,ignoresize=0)) print('\n') print(np_moving_sum(data_1d=data_1d,windowsize=4,ignoresize=3)) print(np_moving_sum(data_1d=data_1d,windowsize=4,ignoresize=2)) print(np_moving_sum(data_1d=data_1d,windowsize=4,ignoresize=1)) print(np_moving_sum(data_1d=data_1d,windowsize=4,ignoresize=0)) print('\n') print(np_moving_average(data_1d=data_1d,windowsize=3,ignoresize=2)) print(np_moving_average(data_1d=data_1d,windowsize=3,ignoresize=1)) print(np_moving_average(data_1d=data_1d,windowsize=3,ignoresize=0)) print('\n') print(np_moving_average(data_1d=data_1d,windowsize=4,ignoresize=3)) print(np_moving_average(data_1d=data_1d,windowsize=4,ignoresize=2)) print(np_moving_average(data_1d=data_1d,windowsize=4,ignoresize=1)) print(np_moving_average(data_1d=data_1d,windowsize=4,ignoresize=0))
実行結果
(base) C:\>python lib_moving_calcs_np.py [1, 2, 3, 5, 8, 13, 21, 34, 55, 89] [ 3. 5. 8. 13. 21. 34. 55. 89. nan nan] [ 5. 8. 13. 21. 34. 55. 89. 144. nan nan] [ 6. 10. 16. 26. 42. 68. 110. 178. nan nan] [ 5. 8. 13. 21. 34. 55. 89. nan nan nan] [ 8. 13. 21. 34. 55. 89. 144. nan nan nan] [ 10. 16. 26. 42. 68. 110. 178. nan nan nan] [ 11. 18. 29. 47. 76. 123. 199. nan nan nan] [ 3. 5. 8. 13. 21. 34. 55. 89. nan nan] [ 2.5 4. 6.5 10.5 17. 27.5 44.5 72. nan nan] [ 2. 3.33333333 5.33333333 8.66666667 14. 22.66666667 36.66666667 59.33333333 nan nan] [ 5. 8. 13. 21. 34. 55. 89. nan nan nan] [ 4. 6.5 10.5 17. 27.5 44.5 72. nan nan nan] [ 3.33333333 5.33333333 8.66666667 14. 22.66666667 36.66666667 59.33333333 nan nan nan] [ 2.75 4.5 7.25 11.75 19. 30.75 49.75 nan nan nan]
DBのテーブルから列データをリストで取得する
DBのテーブルから列データをリストで取得する。fetch()で取得すると、行ごとのタプルのリストになっていて、処理しづらいので、ほしい列の値だけをリストにする関数get_one_column_data_list()を作成。
リストのメモリ確保のため、件数確認のget_countも作成。
get_one_column_data_list()は、リスト化したときの順番をソート済みで取得することも可能。
プログラム
import sqlite3 import random from faker import Faker def get_count(database, table_name): cur = database.cursor() sql_count = "SELECT COUNT (*) FROM {0}".format(table_name) d = cur.execute(sql_count).fetchone() # dは、(100,)のような形になっている cur.close() return d[0] def get_one_column_data_list(database, table_name, column_name, target_column_index=0, column_orderby=None): data_size = get_count(database, "data") data_list = [None]*data_size if column_orderby == None: sql_select = "SELECT {0} FROM {1}".format(column_name, table_name) else: sql_select = "SELECT {0} FROM {1} ORDER BY {2} asc".format( column_name, table_name, column_orderby) cur = database.cursor() d = cur.execute(sql_select) for index, row in enumerate(d): data_list[index] = row[target_column_index] cur.close() return data_list if __name__ == "__main__": con = sqlite3.connect(":memory:") con.isolation_level = None # None で自動コミットモード cur = con.cursor() cur.execute('PRAGMA temp_store=MEMORY;') cur.execute('PRAGMA journal_mode=MEMORY;') sql_create_table = "CREATE TABLE data(number INTEGER UNIQUE, name TEXT, score REAL)" sql_instert_data = "INSERT INTO data VALUES(?,?,?)" fake = Faker() listsize = 8 list_data = [None] * listsize print("データ準備 開始") for i in range(listsize): list_data[i] = [i, fake.name(), random.random()] print(list_data[i]) print("データ準備 完了") cur.execute(sql_create_table) cur.executemany(sql_instert_data, list_data) table_name = "data" column_name = "score" column_orderby = "name" data_list = get_one_column_data_list( con, table_name, column_name, target_column_index=0, column_orderby=column_orderby) print(data_list)
実行結果
>python C:\dev\SampleCodes\hello_sqlite\select_one_col.py データ準備 開始 [0, 'Taylor Smith', 0.6560666934413109] [1, 'Jesse Carrillo', 0.9199740526758551] [2, 'Tina Gonzalez', 0.8344908595983038] [3, 'Richard Mckinney', 0.1240783472168423] [4, 'Victoria Pace', 0.25291942565400816] [5, 'Steven Craig', 0.0703249952634678] [6, 'Valerie Mitchell', 0.0015255246599048533] [7, 'Victoria Hill', 0.9645617001034171] データ準備 完了 [0.9199740526758551, 0.1240783472168423, 0.0703249952634678, 0.6560666934413109, 0.8344908595983038, 0.0015255246599048533, 0.9645617001034171, 0.25291942565400816]